the k8s rabbithole (#4) - k3s and Longhorn

Having run into issues with RKE, I'm going to try K3s instead.
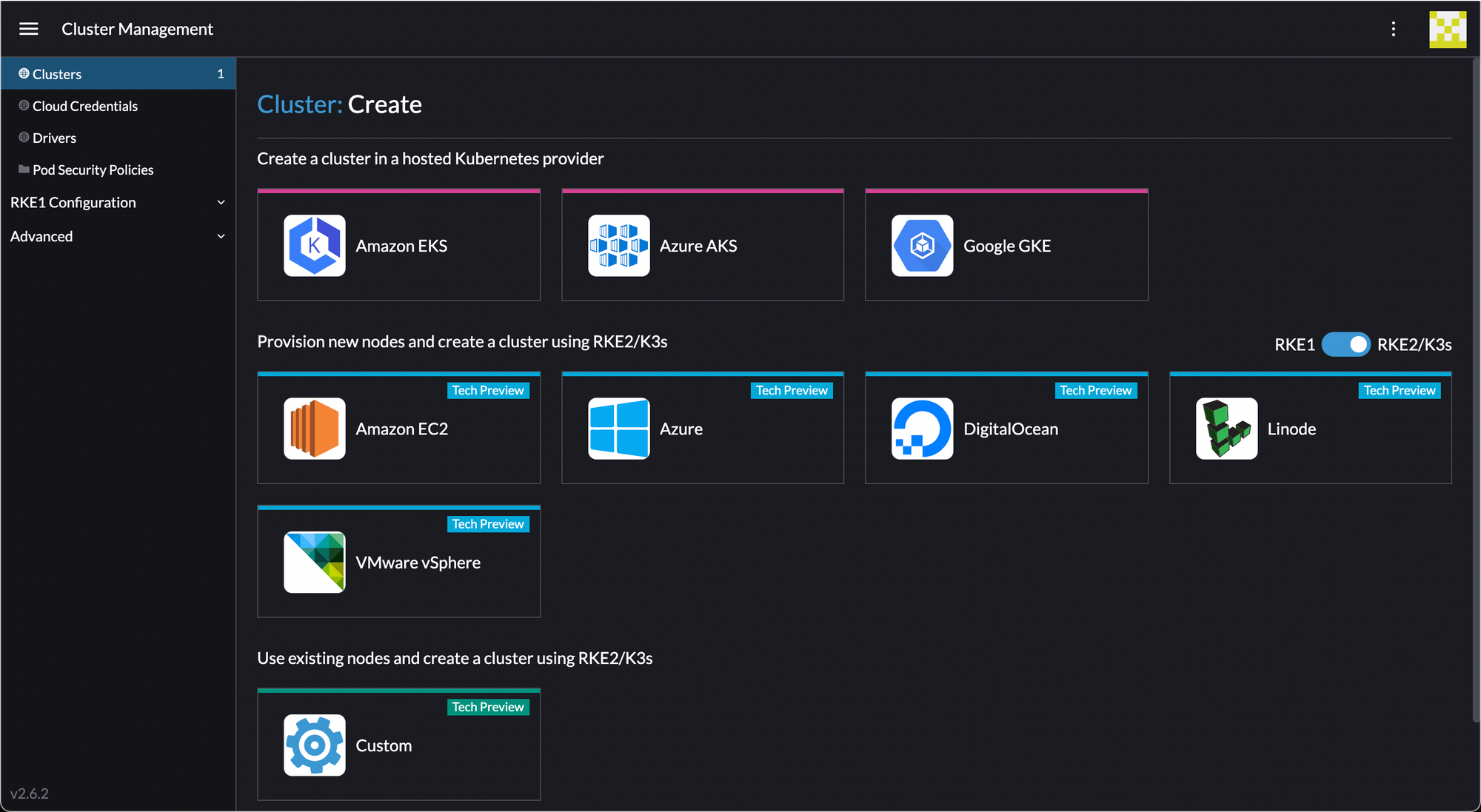
Go back to create a cluster and click the slider to RKE2/K3s.
Select K3s from the dropdown.
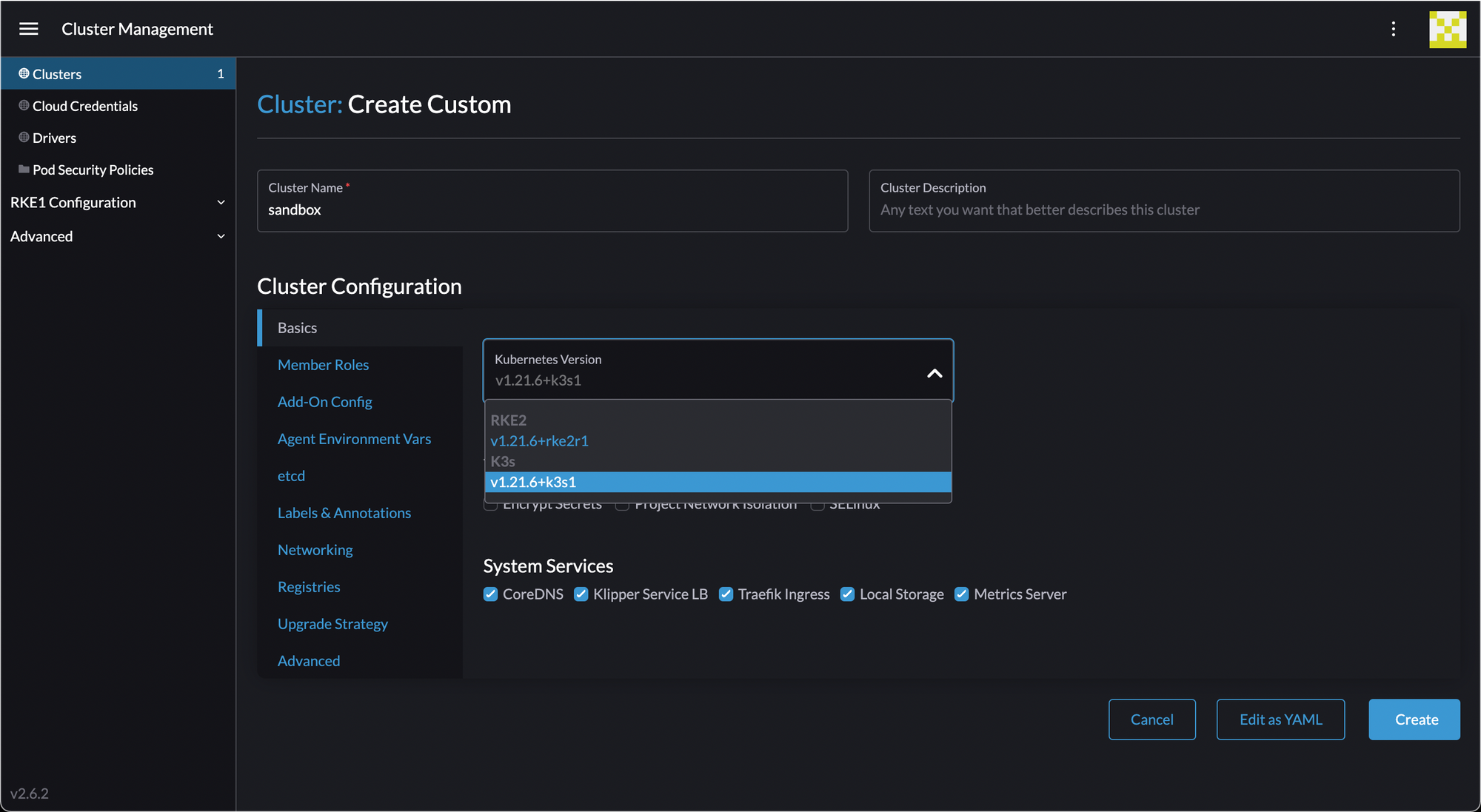
Create the cluster, then provision machines as before (but note it's a different command):
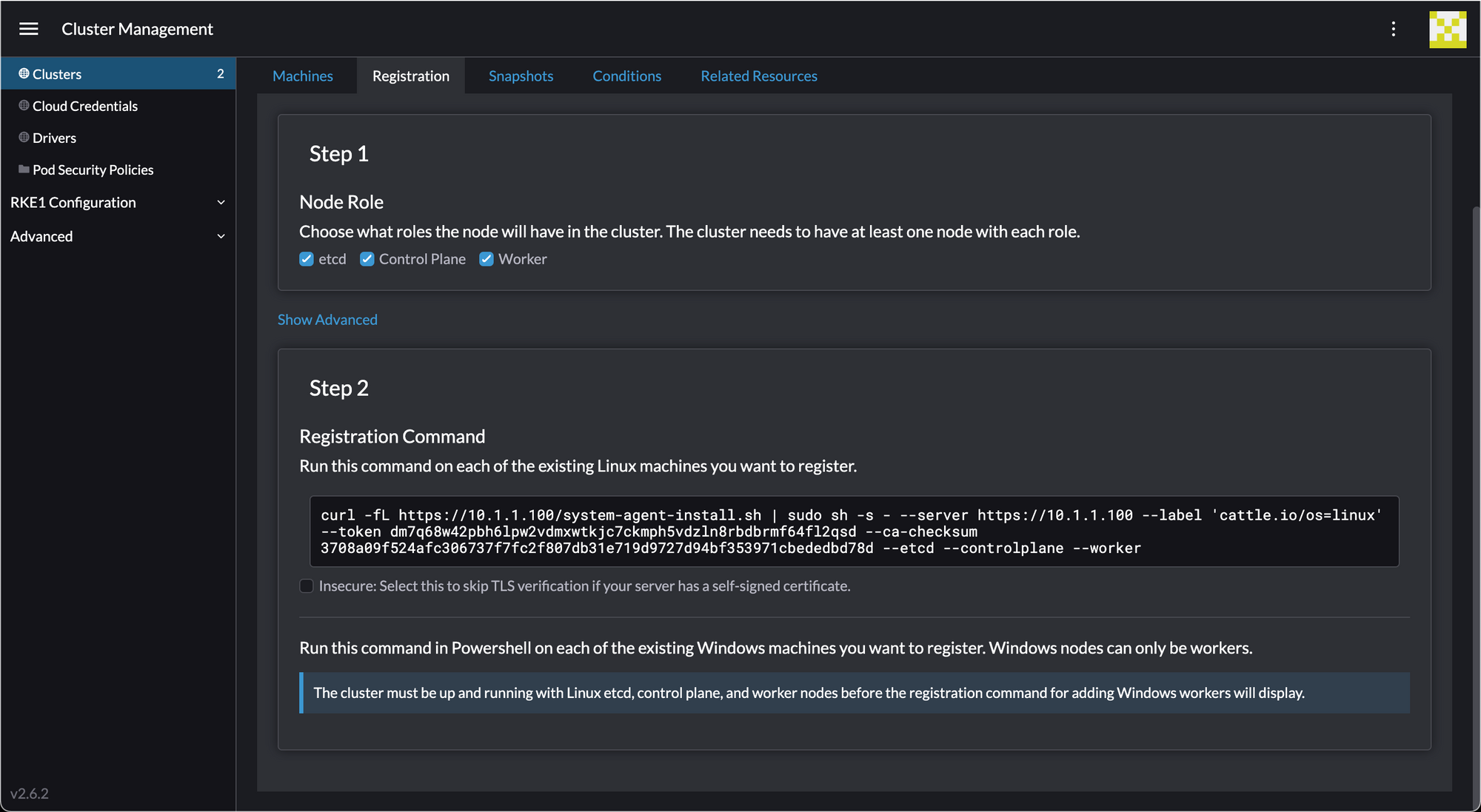
Click "insecure", then copy and paste the commands to each node.
wings@k8s-1:~$ curl --insecure -fL https://10.1.1.100/system-agent-install.sh | sudo sh -s - --server https://10.1.1.100 --label 'cattle.io/os=linux' --token dm7q68w42pbh6lpw2vdmxwtkjc7ckmph5vdzln8rbdbrmf64fl2qsd --ca-checksum 3708a09f524afc306737f7fc2f807db31e719d9727d94bf353971cbededbd78d --etcd --controlplane --worker
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 23735 0 23735 0 0 2317k 0 --:--:-- --:--:-- --:--:-- 2317k
[INFO] Label: cattle.io/os=linux
[INFO] Role requested: etcd
[INFO] Role requested: controlplane
[INFO] Role requested: worker
[INFO] Using default agent configuration directory /etc/rancher/agent
[INFO] Using default agent var directory /var/lib/rancher/agent
[INFO] Determined CA is necessary to connect to Rancher
[INFO] Successfully downloaded CA certificate
[INFO] Value from https://10.1.1.100/cacerts is an x509 certificate
[INFO] Successfully tested Rancher connection
[INFO] Downloading rancher-system-agent from https://10.1.1.100/assets/rancher-system-agent-amd64
[INFO] Successfully downloaded the rancher-system-agent binary.
[INFO] Generating Cattle ID
[INFO] Successfully downloaded Rancher connection information
[INFO] systemd: Creating service file
[INFO] Creating environment file /etc/systemd/system/rancher-system-agent.env
[INFO] Enabling rancher-system-agent.service
[INFO] Starting/restarting rancher-system-agent.service
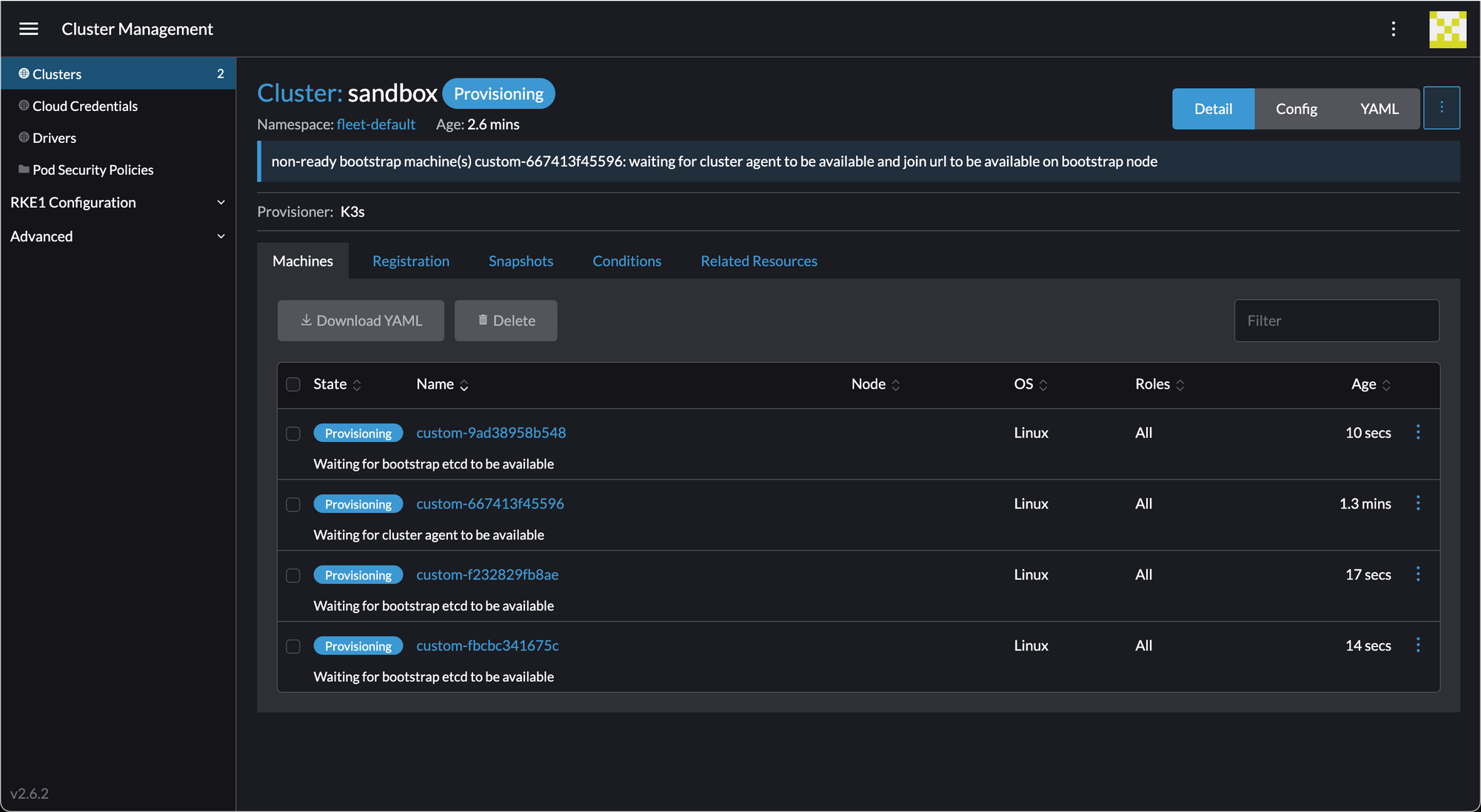
After a few minutes... success! We have a cluster.
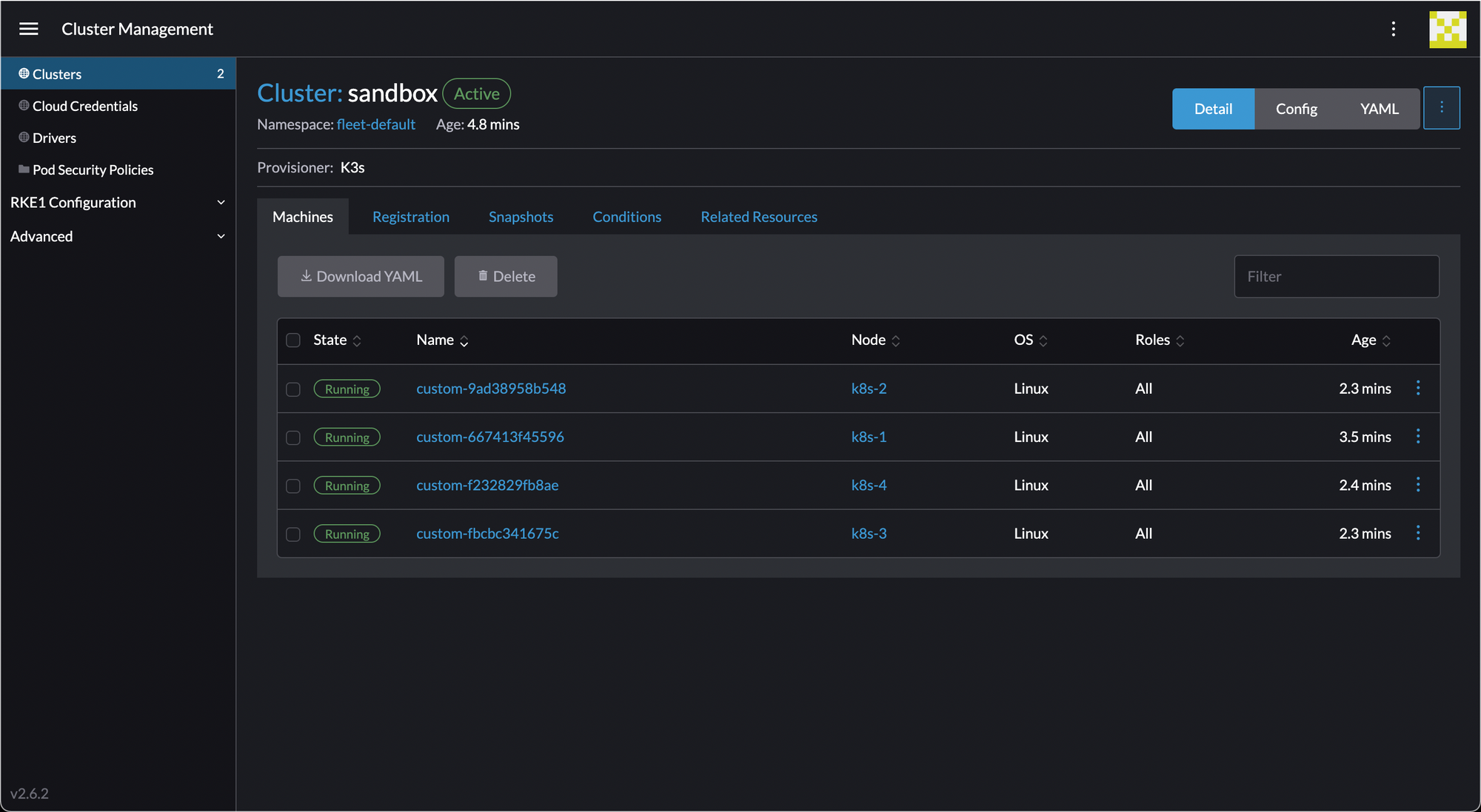
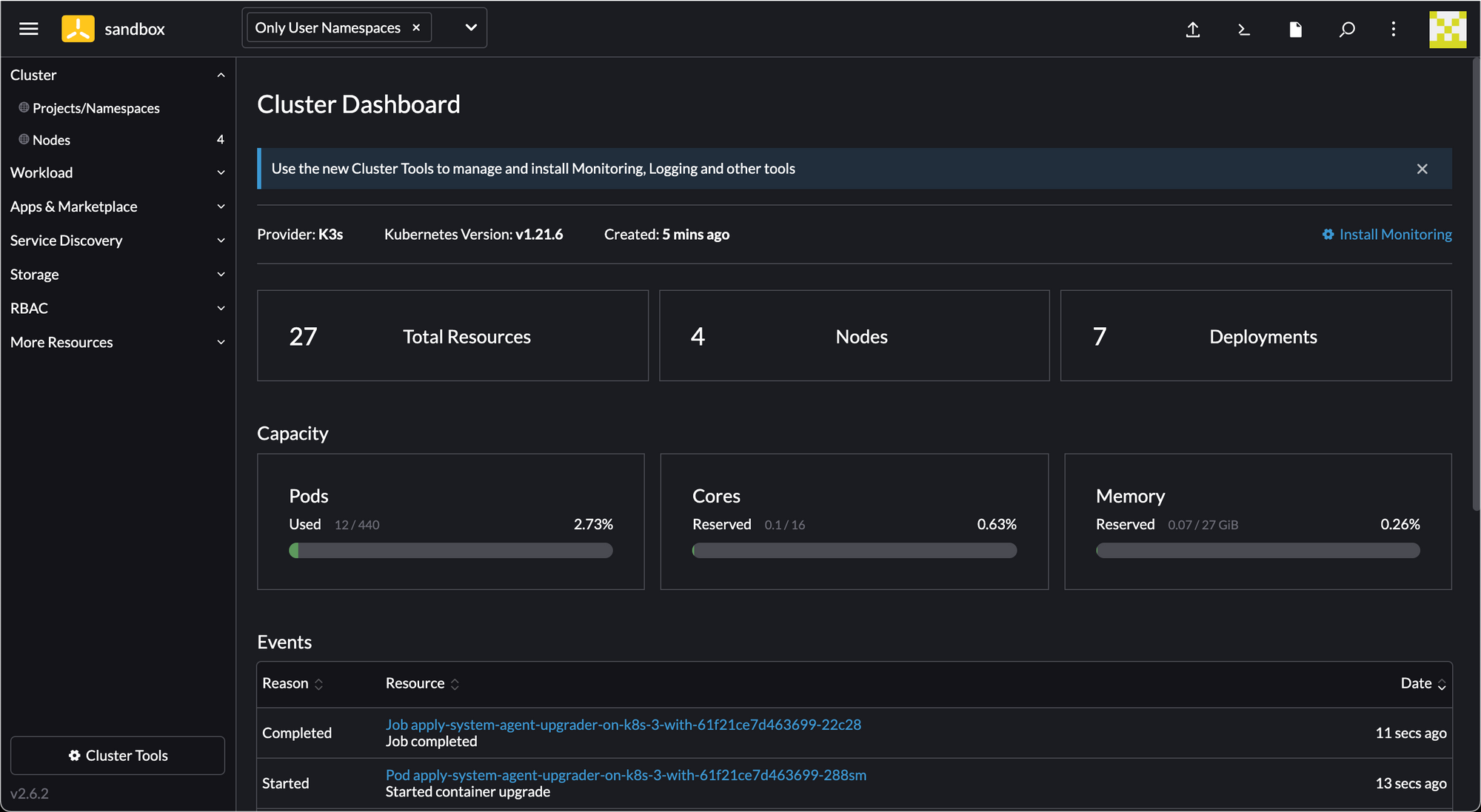
Download the kubeconfig (the button in the top right, to the left of the search button).
Then copy it into place and run our first kubectl command...
wings@trevor ~ % cp ~/Downloads/sandbox.yaml ~/.kube/config
wings@trevor ~ % kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-1 Ready control-plane,etcd,master,worker 5m15s v1.21.6+k3s1
k8s-2 Ready control-plane,etcd,master,worker 2m45s v1.21.6+k3s1
k8s-3 Ready control-plane,etcd,master,worker 2m29s v1.21.6+k3s1
k8s-4 Ready control-plane,etcd,master,worker 3m1s v1.21.6+k3s1
Install Longhorn using the charts...
And open the Longhorn panel to see the state of our cluster.
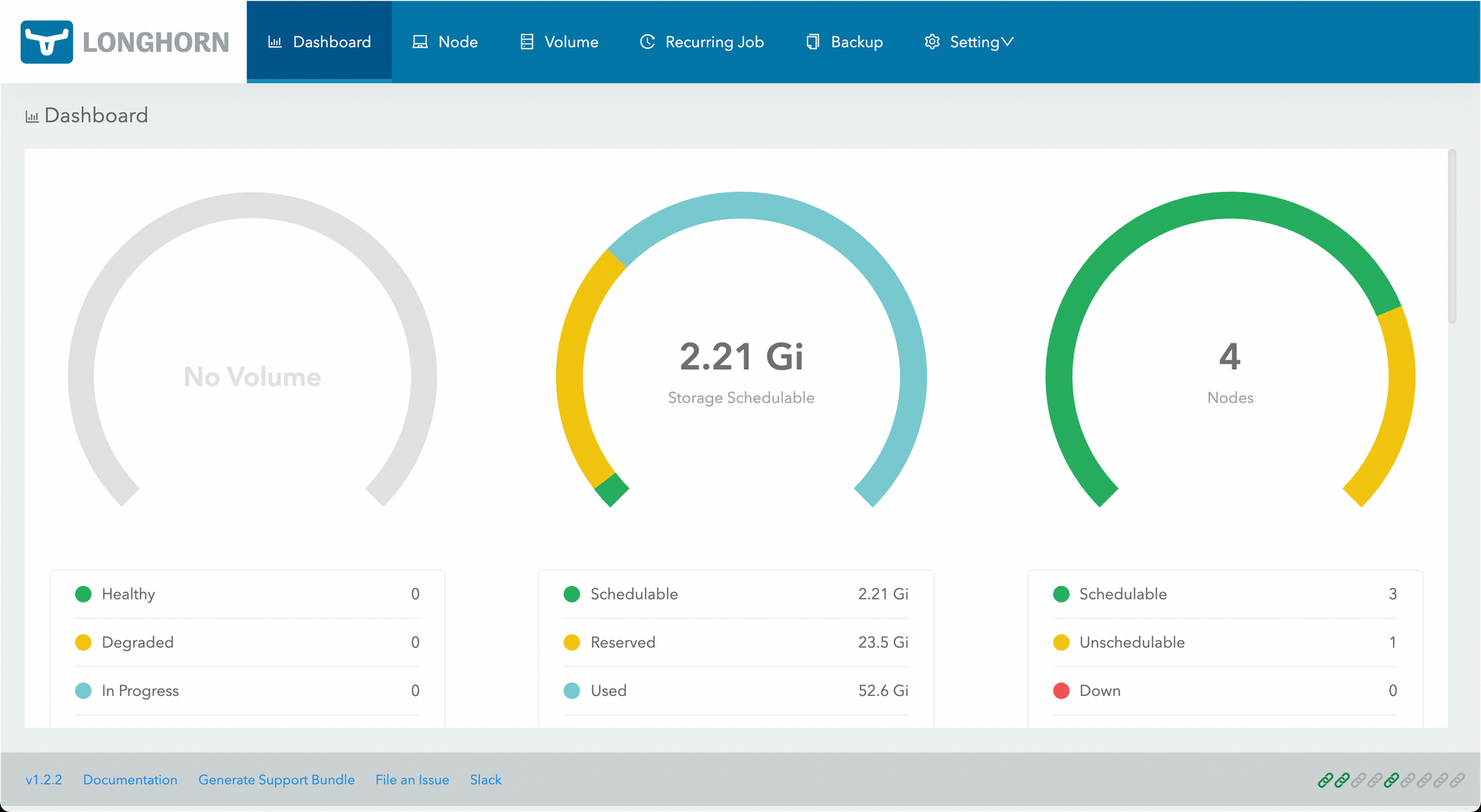
It looks like we don't have a lot of room! Let's fix that. I'll add 50GB disks to each node:
wings@k8s-1:~$ sudo mkfs.ext4 /dev/sdb && sudo mkdir /mnt/brick1/ && sudo mount /dev/sdb /mnt/brick1
mke2fs 1.45.5 (07-Jan-2020)
Creating filesystem with 13107200 4k blocks and 3276800 inodes
Filesystem UUID: 937bd24b-00c7-44aa-a419-1823c09a95a7
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424
Allocating group tables: done
Writing inode tables: done
Creating journal (65536 blocks): done
Writing superblocks and filesystem accounting information: done
Edit disks on k8s-1 and add our new disk:
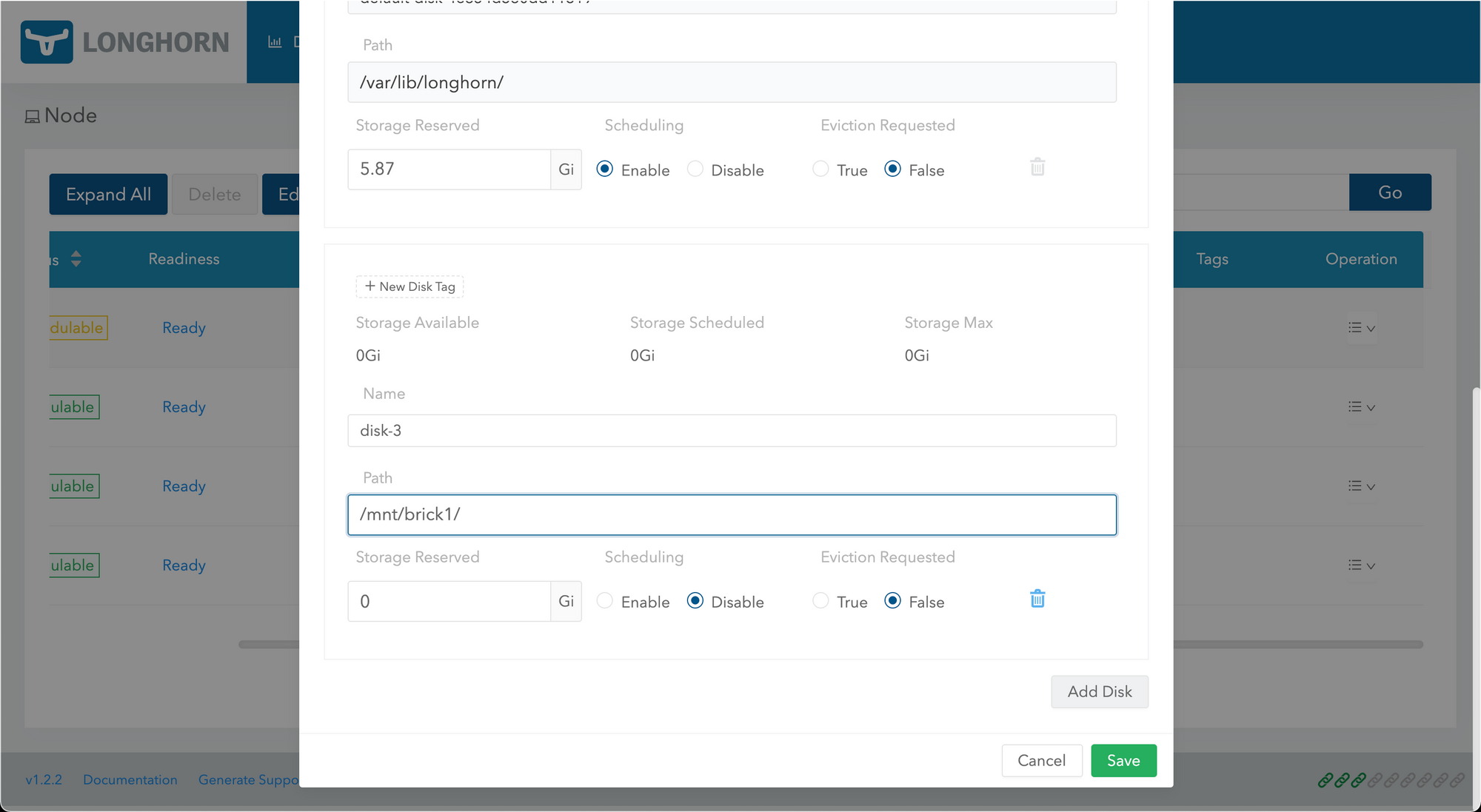
After enabling the disk...
we have storage!
Rinse and repeat for each node...
(and as a sidenote ensure each node will automount its disk)
root@k8s-2:~# echo "/dev/sdb /mnt/brick1 ext4 defaults 0 0" >> /etc/fstab
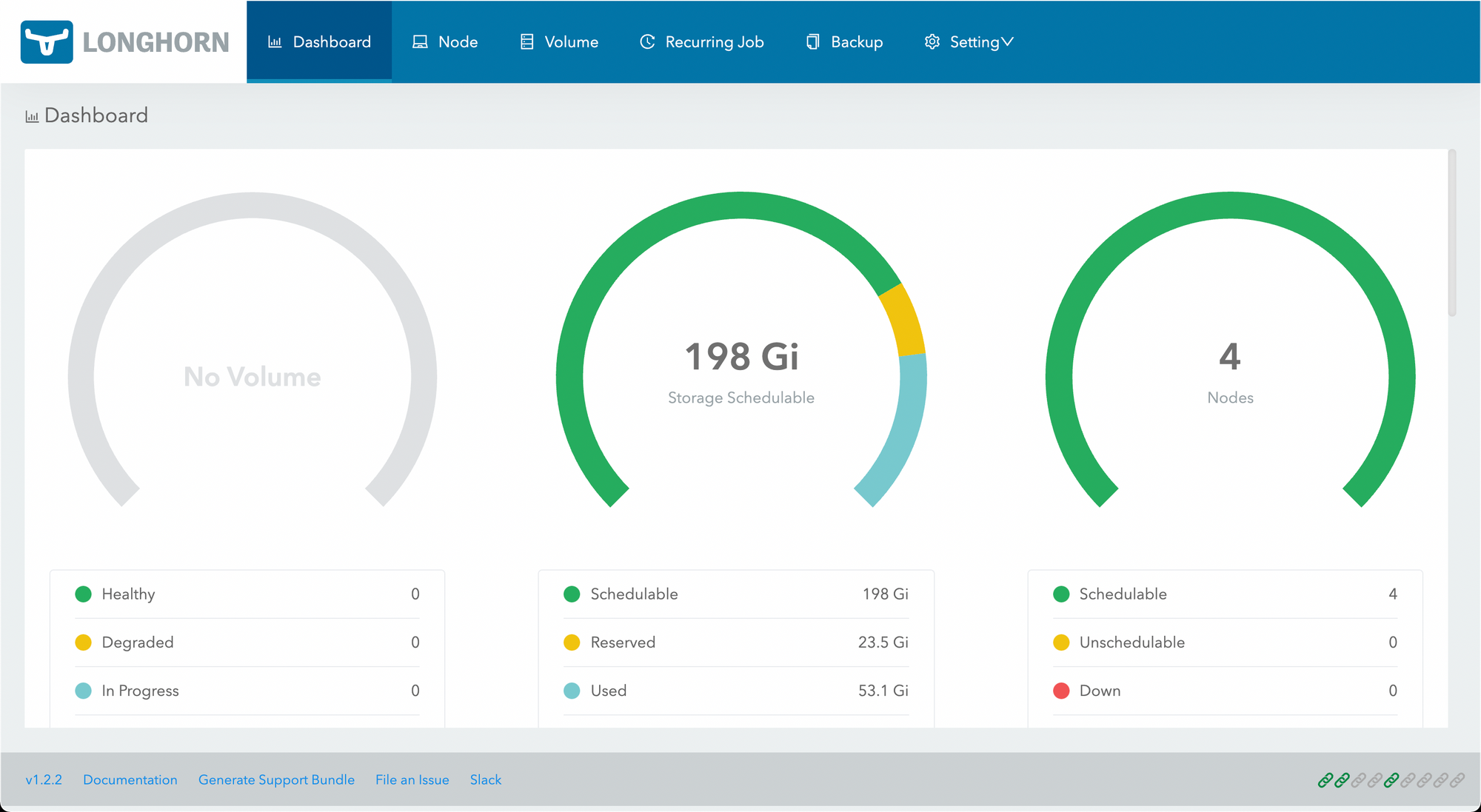
All done! So much room for activities.
Let's install MetalLB using Helm - https://metallb.universe.tf/installation/
wings@trevor ~ % helm repo add metallb https://metallb.github.io/metallb
"metallb" has been added to your repositories
wings@trevor ~ % helm install metallb metallb/metallb
W1123 22:07:33.787515 7588 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W1123 22:07:33.802226 7588 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W1123 22:07:34.102990 7588 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W1123 22:07:34.103007 7588 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
NAME: metallb
LAST DEPLOYED: Tue Nov 23 22:07:33 2021
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
MetalLB is now running in the cluster.
WARNING: you specified a ConfigMap that isn't managed by
Helm. LoadBalancer services will not function until you add that
ConfigMap to your cluster yourself.
Nice! We'll give it 10.1.50.x...
wings@trevor k8s % cat metallb.yaml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: default
name: metallb
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- 10.1.50.1-10.1.50.250
wings@trevor k8s % kubectl apply -f metallb.yaml
configmap/metallb created
In theory MetalLB is now configured, to test it out, let's get Postgres Operator going and create a loadbalancer:
git clone https://github.com/zalando/postgres-operator.git
cd postgres-operator
wings@trevor postgres-operator % helm install postgres-operator ./charts/postgres-operator
NAME: postgres-operator
LAST DEPLOYED: Tue Nov 23 22:16:16 2021
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
To verify that postgres-operator has started, run:
kubectl --namespace=default get pods -l "app.kubernetes.io/name=postgres-operator"
wings@trevor postgres-operator % kubectl --namespace=default get pods -l "app.kubernetes.io/name=postgres-operator"
NAME READY STATUS RESTARTS AGE
postgres-operator-58b75c5587-tqmgj 0/1 ContainerCreating 0 4s
wings@trevor postgres-operator % kubectl --namespace=default get pods -l "app.kubernetes.io/name=postgres-operator"
NAME READY STATUS RESTARTS AGE
postgres-operator-58b75c5587-tqmgj 1/1 Running 0 28s
And install the operator UI:
wings@trevor postgres-operator % helm install postgres-operator-ui ./charts/postgres-operator-ui
NAME: postgres-operator-ui
LAST DEPLOYED: Tue Nov 23 22:17:29 2021
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
To verify that postgres-operator has started, run:
kubectl --namespace=default get pods -l "app.kubernetes.io/name=postgres-operator-ui"
wings@trevor postgres-operator % kubectl get pod -l app.kubernetes.io/name=postgres-operator-ui
NAME READY STATUS RESTARTS AGE
postgres-operator-ui-58644cfcff-cdvp9 0/1 ContainerCreating 0 7s
wings@trevor postgres-operator % kubectl get pod -l app.kubernetes.io/name=postgres-operator-ui
NAME READY STATUS RESTARTS AGE
postgres-operator-ui-58644cfcff-cdvp9 1/1 Running 0 43s
And create a port forward:
wings@trevor postgres-operator % kubectl port-forward svc/postgres-operator-ui 8081:80
Forwarding from 127.0.0.1:8081 -> 8081
Forwarding from [::1]:8081 -> 8081
Now go to http://localhost:8081 in a browser.
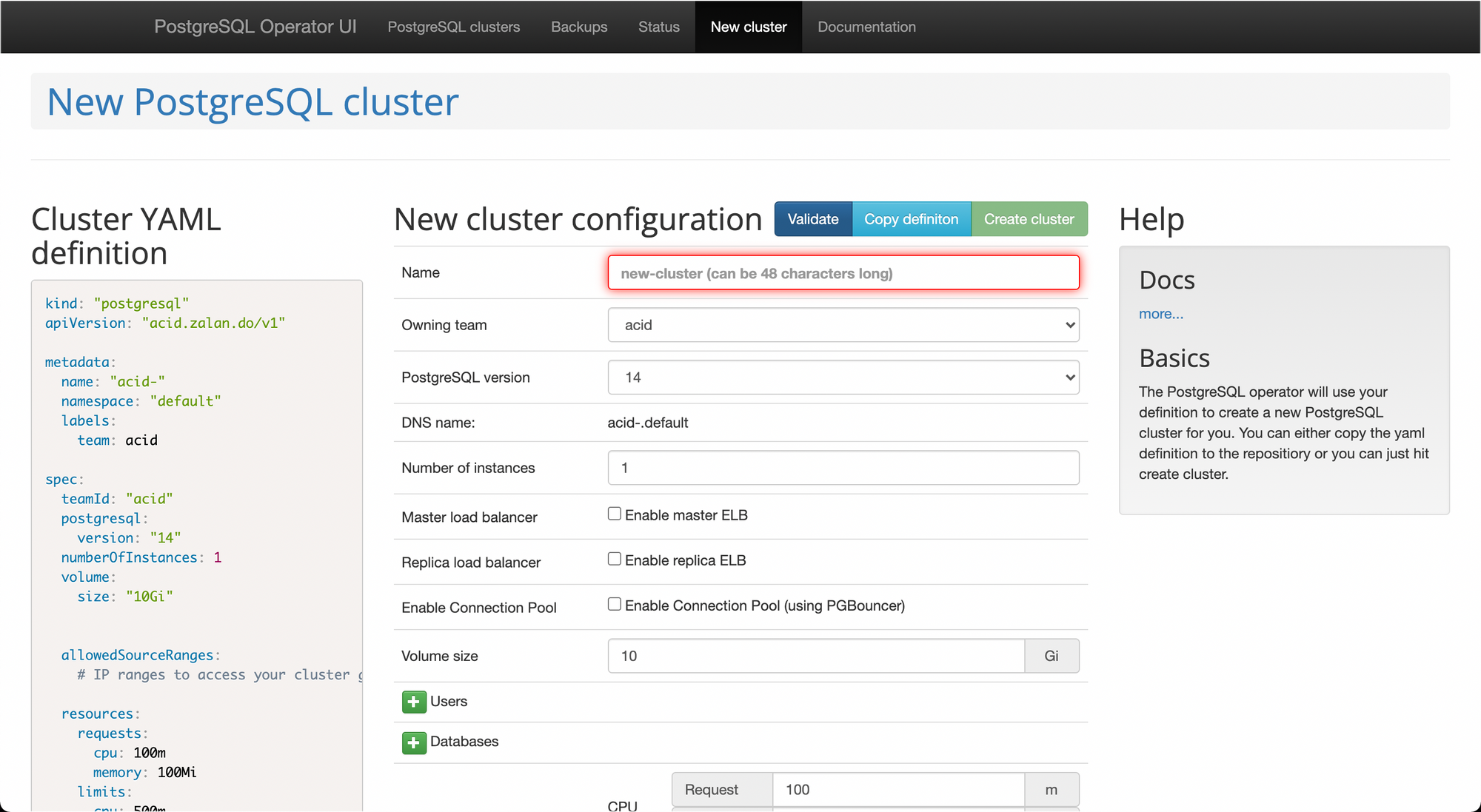
Create a test cluster called "test" and enable loadbalancers.
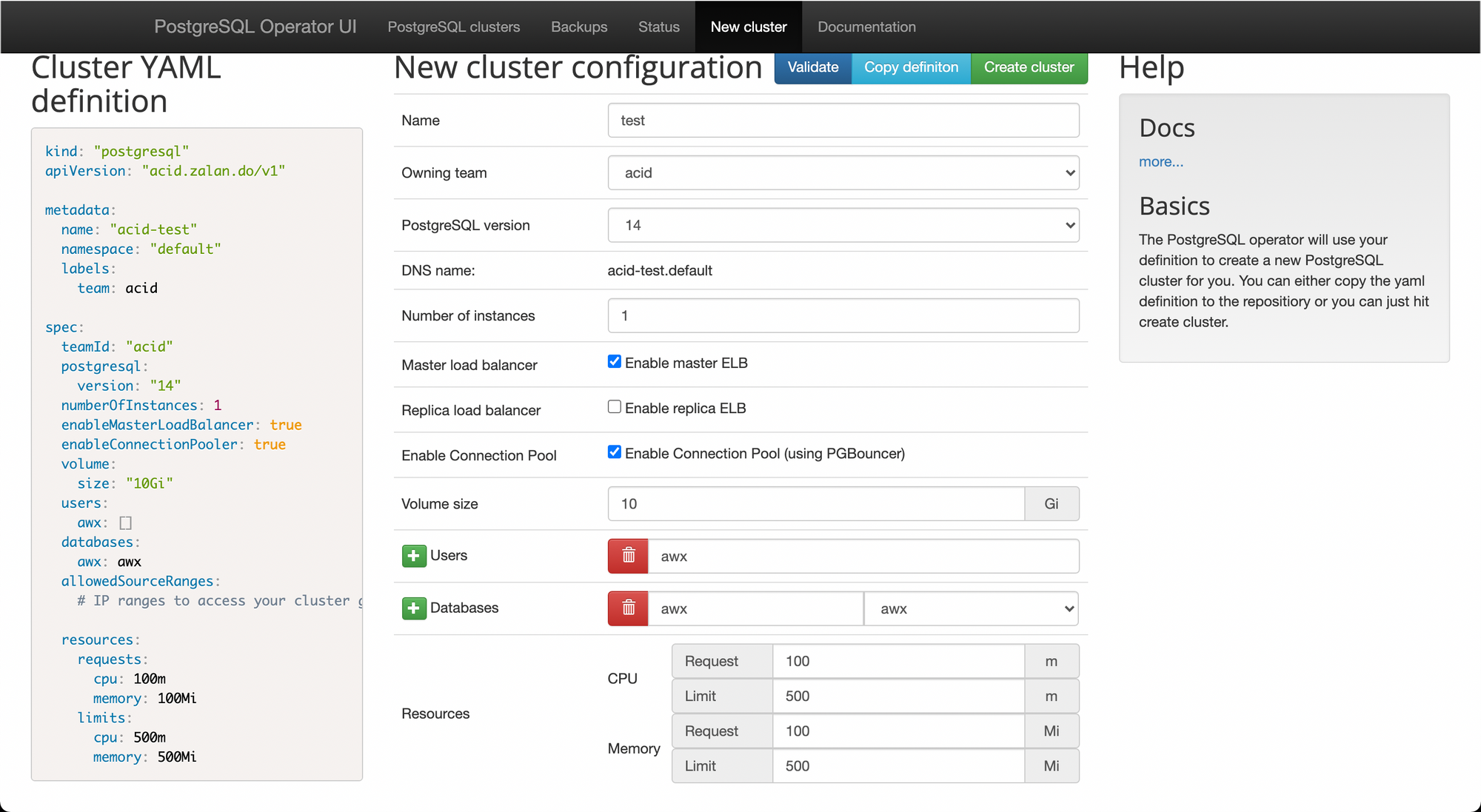
And click Create cluster
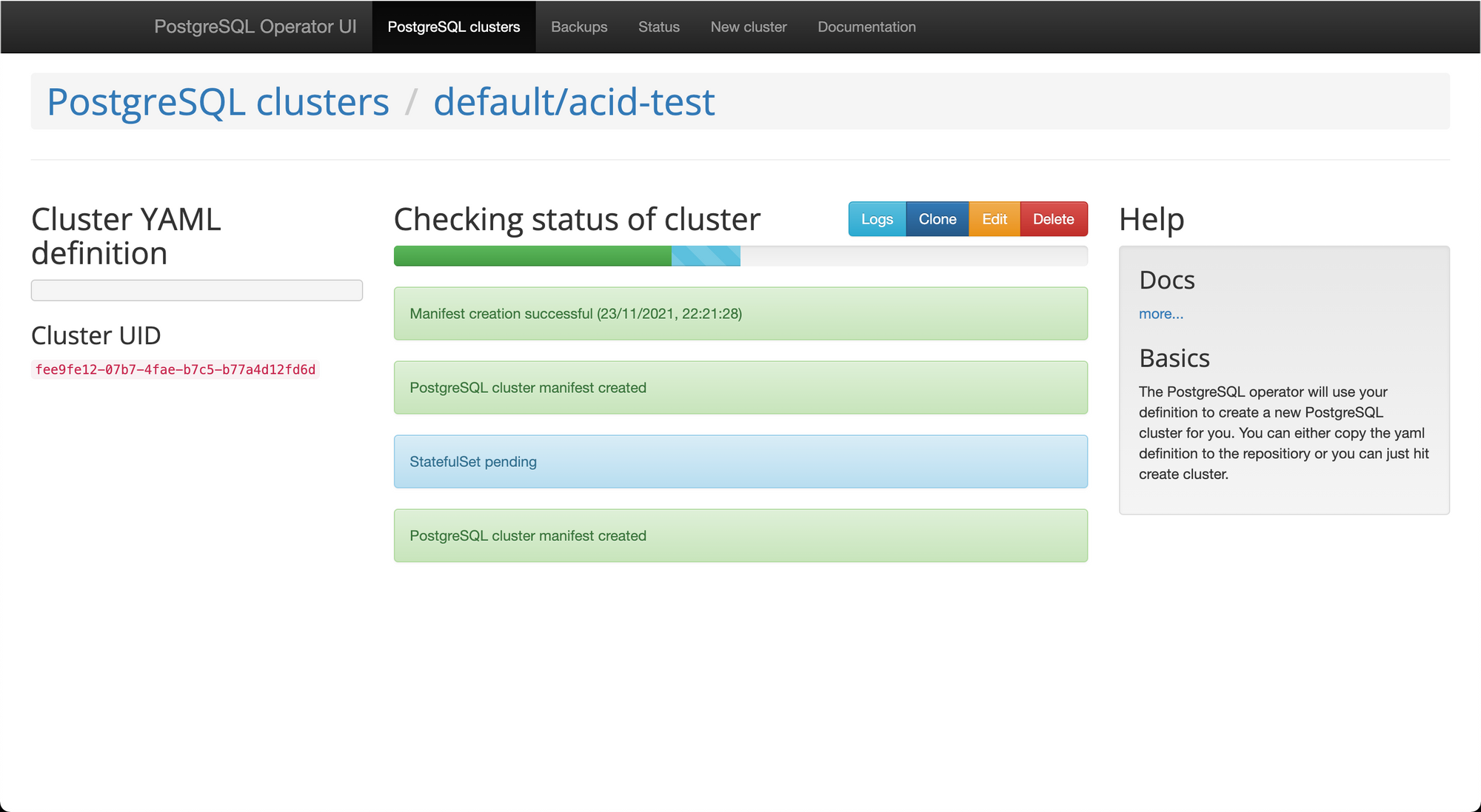
Had to try again after disabling one of the default StorageClasses (enabling longhorn and disabling the stock one)
Got stuck here, possibly something wrong with my lab.