highly available jellyfin: a simple setup


I love streaming.
I don't love having to go to seven different places just to find the show I want to watch. Instead, I use Jellyfin, a free and open source media streaming server.


Jellyfin is great, but one thing I've always wanted out of it is to have it be "highly available", meaning that it withstands events like computers failing and hard drives dying and keeps going through those issues.
This post aims to show a simple and efficient setup of a highly available Jellyfin service, running across 3 physical hosts, utilising a combination of Proxmox, Ceph, Kubernetes and CubeFS.
We'll walk you through the simple, modest homelab that provides the backing services for Jellyfin, and explain how the failover works.
The Lab
Riff Labs Perth is a multi-server deployment, consisting of nodes of roughly the following specs:
- 4x Dual AMD EPYC 7713 64-core nodes with 512GiB of RAM each (SuperMicro AS-2024US-TRT) for a total of 128 cores per server
- 1x Dual AMD EPYC 7773X 64-core node with 128 cores total
- 2x AMD EPYC 7713 64-core node with 512GiB of RAM (SilverStone home built case)
- 1x AMD EPYC 7713 64-core node with 256GiB of RAM (same as above)
- 1x AMD EPYC 7452 32-core node with 512GiB of RAM
All up, there are 864 server grade CPU cores available, and approximately 3.75TiB of RAM.
There is also approximately 2.85 petabytes of hard drive storage (mostly consisting of Seagate Exos X16 16TB hard drives and WD UltraStar DC HC550 16TB hard drives). Not all of the storage is currently online.
Internet is provided by an enterprise grade gigabit fiber connection (shown here during installation, prior to being fully plugged in)

Coheed, Cambria and Creature (the Chatreey and Intel NUCs) form the core services cluster:
- Coheed & Cambria: Chatreey AN1, AMD Ryzen 3550H nodes (4 cores, 8 threads), 32GiB of RAM each
- Creature: ASUS NUC (Intel Core i5-10210u), 16GiB of RAM
Core Services provides things like DNS, DHCP and machine provisioning services for the rest of the homelab.

There is a little bit of storage available to back Jellyfin:


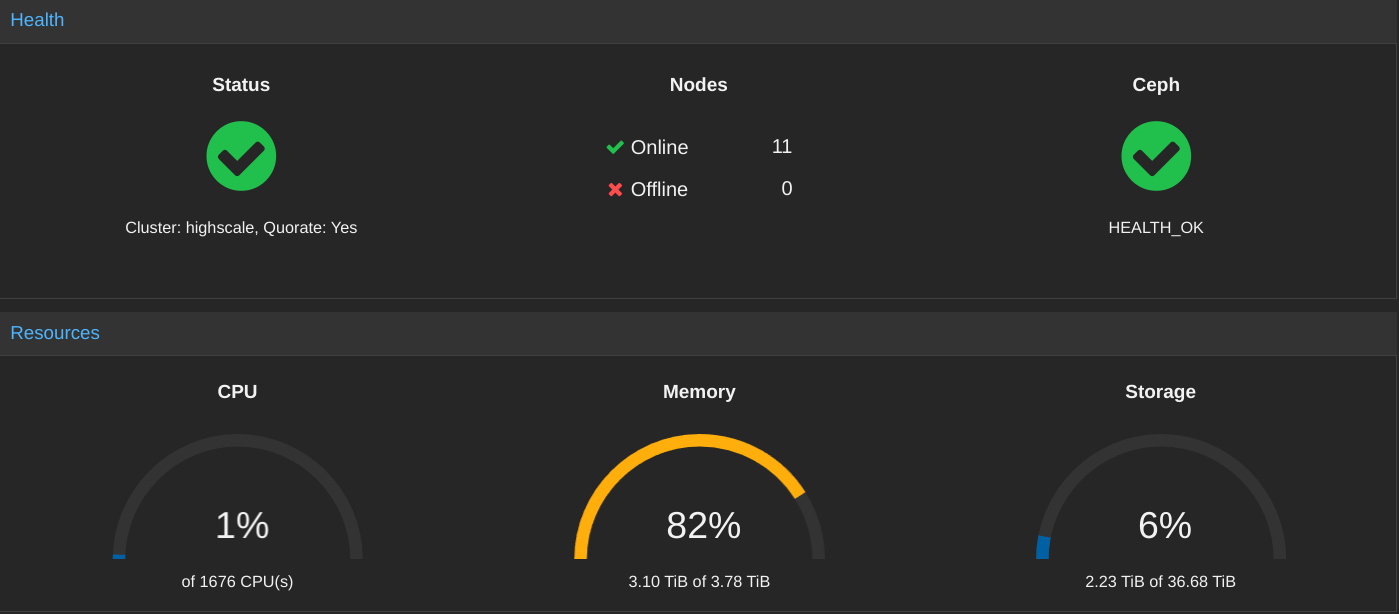
The EPYC nodes as well as the Witch Chickens (the physical Jellyfin servers) form a single Proxmox cluster called Highscale. Within Highscale, Ceph is deployed to provide shared storage for VMs as well as Kubernetes. The Highscale Ceph cluster is powered by an all-flash set of NVMe SSDs attached to a few of the EPYC nodes.
Running on Highscale are 64 Kubernetes workers, which exist as Proxmox virtual machines, each with access to a hardware-accelerated/offloaded network card (Mellanox ConnectX-6 Lx) with two 25Gbps links to a core switch*
*Technically we have a redundant pair of 25gbps switches (the MikroTik CRS518) which is being deployed at the moment, which will upgrade the networking from 10Gbps to 25Gbps. Until then we only have 10 gigabit per second to work with.
On top of the Kubernetes cluster we use Rook to passthrough the Ceph storage from Proxmox into Kubernetes, and allow us to float workloads from machine to machine.
A filesystem called CubeFS is used to combine a number of SAS storage chassis (a mixture of self-built systems, NetApp DS2246/4243/4246 disk shelves, and EMC KTN-STL3 15-bay shelves. The CubeFS infrastructure runs on the Highscale Proxmox cluster as a series of VMs, with the physical nodes themselves directly running the CubeFS Datanode and Metanode services.
Finally, there are three physical computers dedicated (almost) entirely to running Jellyfin:

These three Jellyfin hosts are called Barbara, Ethel and Enid.
Running on the Witch Chickens are three VMs, one on each physical host - jellyfin01, jellyfin02, and jellyfin03. Proxmox passes through the hosts' iGPU (for Intel QuickSync support) through to the VM, where it can then be picked up and used by Kubernetes.
On top of jellyfin01, jellyfin02 and jellyfin03, we run a Kubernetes worker, and these workers are labelled with node labels that allow them to run Jellyfin (no other nodes are eligible for Jellyfin workloads).
All up, we have the following:
- A powerful Proxmox cluster which can run extremely large computing workloads.
- A Ceph cluster running on Proxmox on NVMe SSDs providing fast Ceph storage for Kubernetes workloads.
- A Kubernetes cluster with 64 virtual worker nodes, 3 virtual control plane nodes and 3 special Jellyfin flavoured worker nodes with Intel QuickSync.
- CubeFS providing a petabyte-scale shared media storage system where an unlimited amount of media can be stored safely with automatic replication and data repair.
- A special Jellyfin setup that allows Jellyfin running in Kubernetes to have access to CubeFS and to store its configuration data on Ceph's RBD pools.
What does all of that give you?
Well, it allows you to build a Jellyfin setup that has no dependency on any one physical piece of infrastructure (besides the single internet connection). Hard drives can fail, servers can fail and even switches* (once we swap to the dual MikroTik switches) can fail without taking down Jellyfin.
Here it is in action - in this video, I "physically" power off the VM that is actively running Jellyfin and watch as Jellyfin stops and then automatically recovers within 2.5 minutes.
Jellyfin failing over in the real world.
I've run similar tests with stopping the CubeFS infrastructure one machine at a time, unplugging hard drives and Ceph NVMe drives, and other interruptions, all without Jellyfin skipping a beat (these events have even less impact than powering off one of the Jellyfin servers).
Hopefully you found this post inspiring and you'll go off and build your own little Jellyfin cluster.
addendum
Yes, this post is tongue-in-cheek. You don't need $100K worth of equipment to run Jellyfin, not even if you want to make it highly available.
One interesting thing I had to develop to make this actually work was a way of telling Rook to more aggressively release the storage used for Jellyfin in the event of a node failure. I built a simple tool here -
 Zorlin
ZorlinRook Push automatically manages node taints that allow Rook to reclaim PVCs for use by other nodes.
which is designed to automatically mark offline/dead nodes with the appropriate Kubernetes taints to allow Rook to fence their workloads and let Jellyfin spawn properly.
Besides that, I tweaked RKE2 to allow for faster failover times:
kubelet-arg:
- "node-status-update-frequency=4s"
kube-controller-manager-arg:
- "pod-eviction-timeout=30s"
- "node-monitor-period=2s"
- "node-monitor-grace-period=16s"This allows us to begin failing over Jellyfin within roughly a minute.
Hope you enjoyed reading.
~ B